Menu
.png)
High availability is critical for AI systems that power industries like healthcare, finance, and transportation. Downtime in these systems can lead to financial losses, safety risks, and damaged trust. Designing AI systems with 99.99% uptime - allowing for only about 53 minutes of downtime per year - requires careful planning across redundancy, fault tolerance, scalability, and monitoring.
By integrating these principles, you can build AI systems that remain reliable under pressure, safeguard uptime guarantees, and meet user expectations.
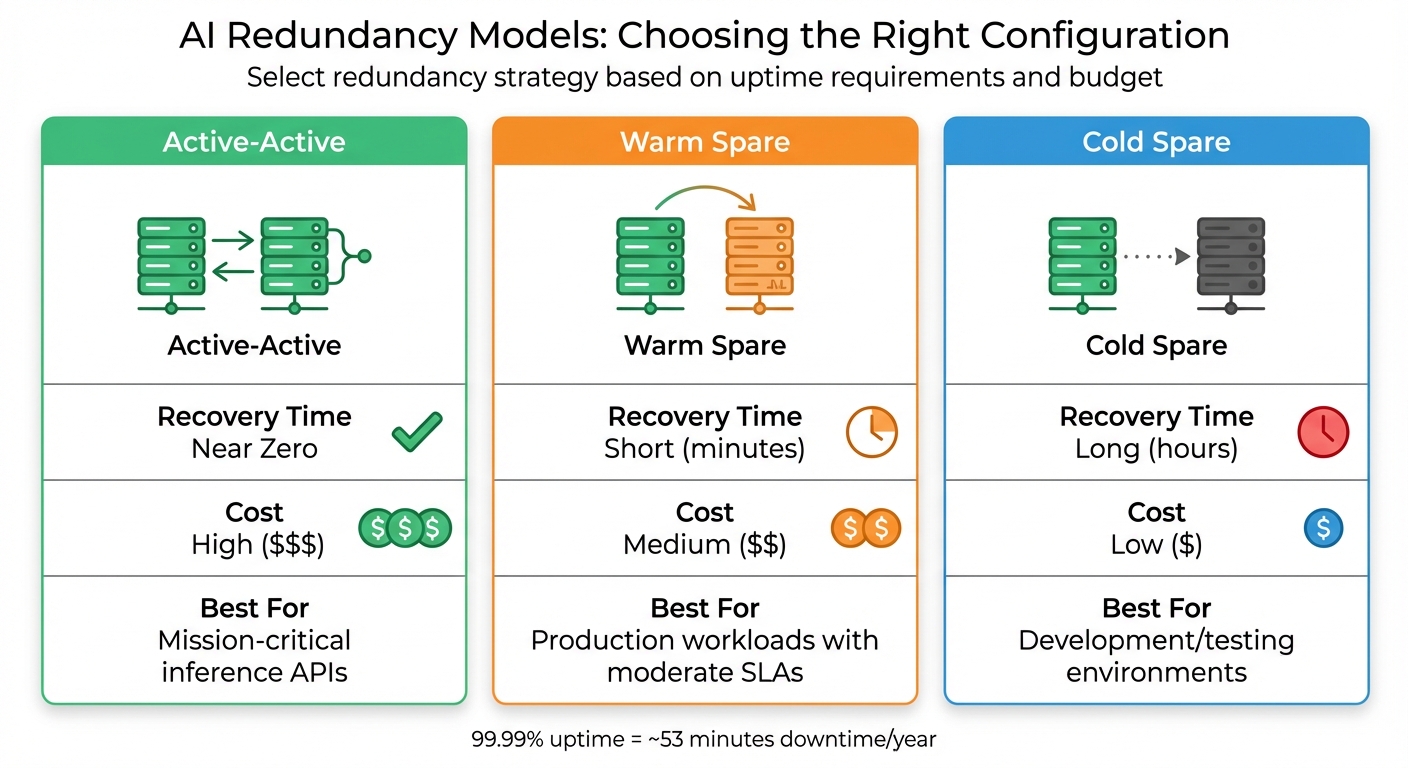
AI High Availability Redundancy Models Comparison: Active-Active vs Warm Spare vs Cold Spare
Redundancy in AI systems involves duplicating critical components to ensure operations continue smoothly, even when failures occur. This encompasses everything from the hardware powering your models to the data pipelines that keep them running.
"A well designed Real Application Clusters system has redundant components that protect against most failures and that provide an environment without single points-of-failure." - Oracle
By eliminating single points of failure, you can create a more resilient AI infrastructure. This requires careful redundancy planning across key areas like hardware, compute, data, and networking. Let’s dive into the common methods and configurations used to achieve this.
AI systems thrive on redundancy across multiple layers:
Two main configurations are used for redundancy:
| Redundancy Model | Recovery Time | Cost | Best For |
|---|---|---|---|
| Active-Active | Near Zero | High | Mission-critical inference APIs |
| Warm Spare | Short (minutes) | Medium | Production workloads with moderate SLAs |
| Cold Spare | Long (hours) | Low | Development/testing environments |
Here’s how redundancy can be applied effectively:
To ensure data redundancy, replicate vector databases across multiple regions and store model checkpoints in dual-region storage buckets (e.g., Azure Blob Storage or Google Cloud Storage). Keeping the compute layer stateless allows inference nodes to be replaced, scaled, or removed without losing application state. This approach supports automated failover and significantly reduces recovery times.
"When you build your workload without infrastructure redundancy, there's a high risk of extended downtime because of potential failures." - Microsoft
Managed services like Azure OpenAI endpoints or Vertex AI simplify the process by handling redundancy automatically. This allows teams to focus on improving model performance rather than wrestling with complex infrastructure configurations.
Fault tolerance takes the concept of redundancy a step further by ensuring your AI system can recover quickly and automatically when something goes wrong. Redundancy lays the groundwork, but the real challenge is designing systems that can detect failures and bounce back with minimal disruption. The goal? Keep things running smoothly even when parts of the system fail.
Fault tolerance means your AI system stays operational despite issues. To achieve this, you need to identify every potential weak spot - whether it’s network connections or GPU hardware - and plan automated responses for each failure scenario. Tools like Failure Mode Analysis (FMA) are essential here. FMA helps map out system components, predict failure points, and define actions like retry policies or failover triggers to handle disruptions effectively.
Creating a fault-tolerant system involves using tried-and-tested design patterns. For example, the circuit breaker pattern is great for preventing cascading failures. It works by isolating faulty components in distributed systems. If latency or error rates exceed a certain threshold, the circuit breaker "trips" and redirects traffic to alternatives like simpler models or cached responses.
Another useful approach is the bulkhead pattern, which partitions services to contain failures. When combined with graceful degradation, this ensures critical functions remain operational, using backups like cached data or switching to read-only modes. For long-running AI training jobs, stateful recovery through checkpointing is a lifesaver. By saving progress at regular intervals to durable storage, the system can resume from the last checkpoint after a failure instead of starting over.
For GPU-heavy workloads, automated hardware monitoring is crucial. For instance, when specific GPU errors (like Xid errors) are detected, the system can take corrective actions such as resetting the GPU or replacing faulty hardware.
Automated failover ensures that traffic or workloads are instantly redirected to healthy standby nodes when failures occur. Multi-region and multi-zone deployments are key to maintaining availability during regional outages or when local resource limits are exceeded. Load balancers with active health checks continuously monitor the status of models and redirect traffic away from unhealthy instances. Model-aware routing takes this a step further by prioritizing instances equipped with the right hardware (like GPUs or TPUs) and enabling failover based on model-specific performance metrics.
"You can't legislate against failure [so] focus on fast detection and response." – Chris Pinkham, founding member of Amazon's EC2 team.
| Mechanism | Function in AI Failover | Best Practice |
|---|---|---|
| Load Balancer | Redirects traffic | Use zone-aware routing to keep traffic local unless a failure occurs. |
| Circuit Breaker | Isolates faulty components | Set thresholds based on metrics like inference latency or error rates. |
| Retry Policies | Handles transient errors | Use exponential backoff to prevent overwhelming recovering services. |
These mechanisms work hand-in-hand with fault-tolerant designs to enable fast and automated recovery.
Testing is a must. Regularly simulating failures - whether it’s a zone outage or a component failure - ensures your system’s recovery processes are up to the task. These "fire drills" validate that your automated failover mechanisms can handle real-world pressure and meet recovery time objectives. Tools like Kubernetes also play a big role, offering self-healing capabilities by automatically restarting failed containers and managing basic recovery tasks.
Scalability plays a vital role in ensuring AI systems can handle growing demands - whether it's more users, larger datasets, or increasingly complex models - without compromising performance or uptime. When scaling is poorly executed, it can lead to performance bottlenecks and inefficient resource use during peak loads. By building on redundancy and fault tolerance strategies, scalability becomes a cornerstone for maintaining a resilient AI infrastructure.
When it comes to scaling, there are two main approaches: vertical scaling and horizontal scaling. Each has its strengths and trade-offs.
Vertical scaling involves boosting the power of a single server by adding more CPU, RAM, or GPU capacity. This method is straightforward since it doesn’t require changes to the system's architecture. However, it has limits - there’s only so much hardware you can add before hitting physical constraints. Plus, relying on a single powerful server introduces a potential single point of failure.
Horizontal scaling, on the other hand, expands capacity by adding more servers or machines to a cluster. This approach enhances availability, as the system can continue functioning even if one node fails. The downside? It requires additional effort to manage load balancing, service discovery, and data consistency across multiple nodes.
| Feature | Vertical Scaling (Scaling Up) | Horizontal Scaling (Scaling Out) |
|---|---|---|
| Method | Adding resources (CPU, GPU, RAM) to one node | Adding more nodes/instances to the pool |
| Complexity | Low; no changes to distributed logic needed | High; requires load balancing and service discovery |
| Availability | Lower; single node is a potential point of failure | Higher; redundancy and fault tolerance included |
| Limit | Limited by single server hardware capacity | Virtually limitless; more nodes can be added |
| AI Use Case | Ideal for initial model development or small-scale inference | Suited for large-scale inference pipelines and distributed training |
For production AI workloads, horizontal scaling is typically the go-to option. For example, NVIDIA's H200 NVL platform demonstrates scalability by networking multiple servers to support distributed AI training and high-performance computing tasks.
"Scaling out doesn't fix every performance issue. For example, if your backend database is the bottleneck, it doesn't help to add more web servers." – Microsoft Azure Well-Architected Framework
AI systems come with unique challenges that demand tailored scaling strategies. For instance, enterprise GPUs often operate at only 15–20% utilization due to outdated infrastructure, emphasizing the need for continuous monitoring to optimize resource usage and avoid costly idle hardware.
When dealing with distributed training, high-bandwidth, low-latency networking between GPUs is critical. Poor inter-node communication can create bottlenecks that significantly slow down training tasks. Modern AI models, especially those using test-time scaling, can amplify compute needs by over 100x for a single query, as they run multiple inference passes to enhance accuracy.
To effectively implement horizontal scaling, stateless service design is key. This means AI services should process any request without relying on local session data, allowing any instance in the system to handle incoming queries. Tools like container orchestration platforms enable automated scaling and self-healing capabilities. For long-running tasks, such as video processing or advanced reasoning, asynchronous processing with message queues (e.g., RabbitMQ or Kafka) ensures smoother operation and better resource management.
Distributing AI model deployments across multiple regions can also safeguard availability during local outages or when hitting quota limits in specific zones. Auto-scaling groups with target tracking policies, such as maintaining a 50% average GPU utilization, can dynamically adjust the number of instances based on real-time demand. This approach prevents performance dips during traffic spikes while cutting costs during off-peak hours, when CPU usage can drop by as much as 90%.
Resilient systems don’t just rely on redundancy and fault tolerance - they also need solid monitoring and automated recovery to stay operational. Even the most advanced AI setups can encounter unexpected problems, and the speed at which those problems are identified and resolved often determines whether they remain minor issues or escalate into major outages.
AI systems require a mix of traditional infrastructure monitoring and specialized performance tracking. On the infrastructure side, keeping an eye on CPU usage, memory load, and disk space is critical to avoid timeouts or crashes caused by resource shortages. For AI-specific needs, factors like GPU and TPU utilization and hardware errors (e.g., Xid errors) can directly impact the performance of training and inference tasks.
Generative AI and large language models come with their own set of metrics to watch. Token throughput, queries per second (QPS), and first token latency are all essential for ensuring a smooth user experience. In distributed AI environments, network reliability is another priority. Monitoring packet loss, bandwidth usage, and latency helps catch connectivity issues before they disrupt workflows.
Storage health is equally important. Any dip below 100% storage availability in cloud environments could indicate failing write operations. To put this into perspective, Google Cloud Monitoring tracks over 65 quadrillion data points on disk - a testament to the scale of modern monitoring systems.
A good strategy for monitoring AI services involves defining clear health states like healthy, degraded, and unhealthy. Automated health probes from multiple global locations can verify that services remain accessible to users everywhere. For applications like web APIs, synthetic monitoring - using automated scripts to simulate user interactions - helps detect performance problems or slowdowns in real time.
To ensure monitoring doesn’t interfere with system performance, asynchronous logging can be used to avoid application delays. Additionally, focusing on Service Level Objectives (SLOs) tied to user-centric outcomes - rather than just technical metrics - provides a clearer picture of how system health impacts customer experience.
| Metric Category | Key Metrics to Track | Purpose for AI High Availability |
|---|---|---|
| Compute/Accelerator | GPU/TPU Utilization, Xid Errors | Ensures hardware is functioning for training/inference |
| Generative AI | Token Throughput, First Token Latency | Tracks responsiveness of large language models |
| Infrastructure | CPU/Memory Pressure, Disk I/O | Identifies resource bottlenecks impacting services |
| Network | Latency, Packet Loss, Bandwidth | Detects connectivity problems in distributed systems |
| Storage/DB | Query Duration, Timeouts, Locks | Monitors data layer performance for AI workloads |
Good monitoring doesn’t just flag issues early - it also lays the groundwork for fast recovery.
When monitoring systems detect a problem, quick automated recovery is essential to maintain uptime. For long-running AI training tasks, checkpointing is a must. It allows systems to resume from the last saved state instead of starting over after an interruption. Similarly, circuit breakers in distributed AI setups can isolate failures to prevent cascading issues.
If a primary model or specialized hardware fails, graceful degradation can keep services running by switching to simpler models or cached data. Deploying AI models across multiple regions or zones, combined with global load balancers, ensures traffic is routed away from unhealthy instances automatically.
Hardware issues, like GPU Xid errors, can trigger automated corrective actions such as resetting or replacing faulty components. For stateless components, rather than repairing failures, it’s more effective to replace them with fresh instances - this immutable infrastructure approach ensures consistency and simplifies recovery.
Recovery monitoring is just as important as failure detection. Alerts for recovery events help teams track how quickly systems bounce back and refine their processes accordingly. Using correlation IDs to trace transactions across the system can also help differentiate between temporary glitches and persistent issues that demand immediate attention.
Creating AI systems with high availability isn't just about keeping systems online - it's about ensuring they perform reliably under any circumstances. This requires expertise in redundancy, scalability, and fail-safe design. Artech Digital specializes in turning these principles into production-ready solutions that reduce downtime and maintain consistent performance. Their approach lays the groundwork for a scalable, resilient architecture capable of meeting stringent uptime demands.
One of Artech Digital's standout strategies is its use of Failure Mode Analysis (FMA) to pinpoint potential risks early in the design process. They employ multi-region deployments combined with load balancing techniques - like round-robin or weighted routing - that automatically redirect traffic to healthy instances if a region encounters an outage or hits capacity limits. For businesses aiming for near-perfect uptime - where 99.99% availability means only a few minutes of downtime annually - geographically distributed systems are non-negotiable.
To handle scalability, Artech Digital employs dynamic resource management. By leveraging horizontal autoscaling based on real-time GPU or TPU usage, they ensure systems perform smoothly during peak demand while keeping costs in check during quieter periods. Their experience with containerized platforms like Google Kubernetes Engine (GKE) allows for modular and loosely connected system designs. This means that if one component - say, data ingestion - fails, it doesn't bring the entire system down. Managed services further ease operational complexities by handling redundancy and replication seamlessly in the background.
Fault tolerance is another cornerstone of Artech Digital’s approach. They implement design patterns like circuit breakers and graceful degradation, which allow systems to keep running even when some components fail. Automated failover mechanisms detect problems and switch operations to backup systems instantly. Meanwhile, Infrastructure as Code (IaC) tools ensure deployments remain consistent and easily recoverable, even across multiple regions. In addition, centralized API management enforces rate limits and handles error responses, maintaining service quality during high-stress situations.
This combination of monitoring, automated recovery, and robust design empowers businesses to deploy AI-driven tools like web apps, chatbots, computer vision solutions, and advanced language models. Whether using N+1 redundancy for load balancing or a 2N active-standby configuration, Artech Digital tailors the infrastructure to meet the specific availability needs of each workload, ensuring seamless operation no matter the challenge.
Building resilient AI systems hinges on ensuring high availability. As Microsoft aptly puts it, "Failure is impossible to avoid in a highly distributed hyperscale cloud environment like Azure. By anticipating failures and correlated impact... a solution can be designed and developed in a resilient manner". This perspective shifts the goal from trying to eliminate every failure to creating systems that can withstand and recover from them.
To recap the key principles, layering multiple protections is crucial for resilience. Redundancy across compute, data, and networking layers prevents any single point of failure. Techniques like circuit breakers and graceful degradation ensure systems continue operating even when parts encounter issues. Horizontal scaling, in particular, is vital for handling traffic surges without sacrificing performance. Additionally, monitoring AI-specific metrics - such as GPU usage, model drift, and first-token latency - helps identify potential problems early.
Keeping things simple often outperforms complex solutions. Google Cloud highlights that "Reliable AI and ML systems in the cloud require scalable and highly available infrastructure... Scalable architectures adapt to fluctuating loads and variations in data volume or inference requests". Leveraging tools like managed services, Infrastructure as Code, and active-active deployments minimizes manual intervention while boosting consistency and recovery speed. This disciplined approach not only enhances reliability but also ensures operational efficiency.
The design strategies outlined earlier serve as the backbone of robust AI infrastructures. Systems that meet Service Level Agreements safeguard revenue and foster user confidence. Practices like regular Failure Mode Analysis, failover testing, and automated recovery turn theoretical designs into production-ready solutions that can tackle real-world challenges. These measures ensure AI workloads remain dependable when they’re needed most.
Active-active redundancy brings major advantages to AI systems by promoting greater availability and fault tolerance. In this configuration, traffic is shared among multiple active instances, often spread across various zones or regions. Unlike active-passive setups, this approach eliminates idle standby resources and significantly reduces failover delays.
By distributing the workload continuously, active-active redundancy not only boosts system performance but also enhances reliability. This makes it a perfect fit for essential AI tasks that demand uninterrupted operation and smooth user experiences.
A circuit breaker pattern acts as a safety mechanism for AI systems by keeping an eye on remote calls to services like model inference, feature stores, or APIs. If failures, timeouts, or latency spikes go beyond a defined limit, the circuit breaker switches to an open state. In this state, it blocks further calls and immediately returns an error or fallback response. This helps prevent critical resources like memory or network sockets from being overloaded, stopping failures from spreading to other parts of the system.
When the affected service shows signs of recovery, the breaker shifts to a half-open state, allowing a small number of test requests to go through. If these test requests are successful, normal operations restart. If they fail, the circuit returns to the open state, repeating the process. This method works alongside other strategies for high availability, ensuring AI pipelines stay robust and responsive, even during disruptions.
Artech Digital incorporates circuit breaker patterns into its AI solutions to boost the reliability of custom machine learning models, fine-tuned LLMs, and other AI-powered workflows.
Horizontal scaling means increasing the number of servers or computing nodes to share workloads across multiple systems. This method improves system reliability, ensures continuous availability, and helps AI systems manage growing traffic and data demands without compromising efficiency.
By distributing tasks across several nodes, horizontal scaling minimizes the chances of system outages and keeps services running smoothly, even during high-demand periods. It’s a practical and budget-friendly way to ensure AI workloads can grow while maintaining both performance and stability.
.png)

.png)