Menu
%20(1).png)
AI-ready data infrastructure ensures high-quality, accessible, and secure data to support AI systems effectively. However, most organizations face challenges like poor data quality, silos, and outdated systems, which hinder AI scalability. This article covers key strategies to prepare your data infrastructure for AI, including:
Organizations that prioritize scalable, secure, and well-governed data systems can unlock the full potential of AI while minimizing risks and inefficiencies.
AI Data Infrastructure: Key Statistics and Impact Metrics
Data governance is all about setting clear rules for how data is collected, stored, accessed, and used. It ensures that data remains accurate, secure, and compliant - key ingredients for successful AI implementation. A well-designed framework not only maintains data quality but also ensures that the right teams can access it when needed.
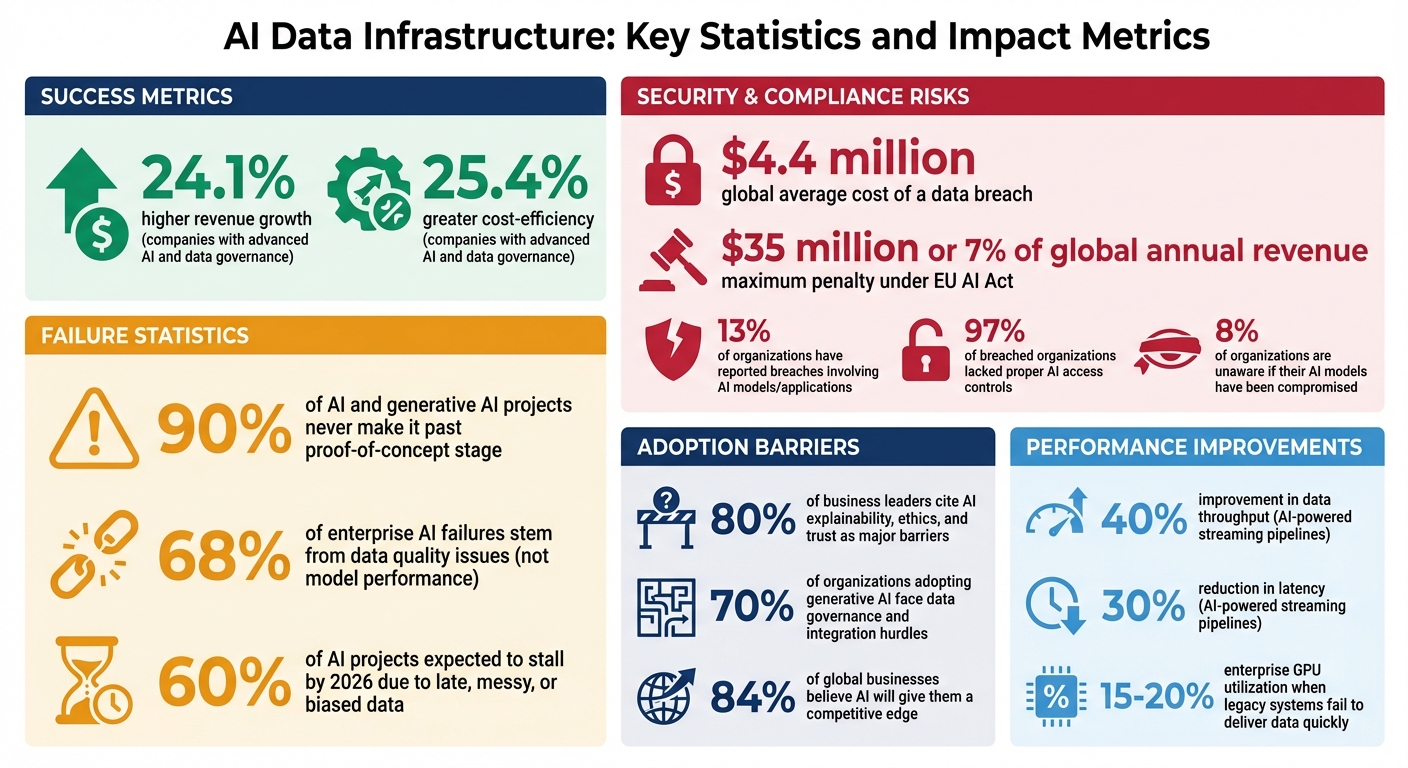
Organizations with strong governance frameworks consistently outperform their competitors. For instance, companies with advanced AI and data governance practices report 24.1% higher revenue growth and 25.4% greater cost-efficiency compared to less mature organizations. The stakes are high: the global average cost of a data breach has hit $4.4 million, and penalties under the EU AI Act can soar to $35 million or 7% of a company’s global annual revenue. These figures highlight why robust governance is essential.
"You can't have AI without quality data, and you can't have quality data without data governance." - Databricks
Standardized policies are the backbone of effective data governance. They prevent confusion and ensure consistency across AI projects. Begin by crafting a standard data dictionary - a document that defines every data element in your organization, including its format, acceptable values, and measurement units. This eliminates the risk of different departments using conflicting definitions for the same metric.
Your policies should address data classification, access controls, and usage guidelines. For example, you can implement fine-grained access controls like row filters and column masks to secure sensitive data while allowing authorized access. Ensure uniformity by standardizing naming conventions, U.S. date formats (MM/DD/YYYY), and imperial measurement units across all databases.
Accountability is another key element. Assign data stewards to handle daily quality checks and resolve issues, while data owners manage access rights and ensure compliance with regulations. Many organizations also appoint a Chief Data Officer (CDO) to oversee governance efforts and coordinate across departments.
Automated tools can make managing data much easier. They classify, tag, and track data across your systems efficiently. A centralized metadata repository serves as a "single source of truth", cutting down on redundancy and avoiding confusion caused by conflicting taxonomies.
Data lineage tracking is another critical feature. It lets you trace how data evolves - from its original source to its final use in AI models. This is invaluable for troubleshooting errors in models and assessing the impact of changes in upstream data sources. When AI models deliver unexpected or inaccurate results, lineage tracking can help pinpoint where things went wrong.
AI-powered tools further enhance this process by automatically generating metadata descriptions and tags for datasets. This speeds up data discovery and classification while flagging sensitive information - like financial or health records - before it enters AI pipelines. Automated quality checks, or "expectations", ensure incoming data meets required standards before processing begins.
Compliance isn’t optional - it’s a necessity. Industry-specific regulations like HIPAA, CCPA, and GDPR must be followed to avoid hefty fines.
One way to ensure compliance is by enabling audit logging, which tracks who accesses datasets and what actions they take. These logs are crucial during audits or investigations. Regular risk assessments can also help monitor your AI models for performance issues, bias, or new security vulnerabilities.
Consider adopting established frameworks like the NIST AI Risk Management Framework or ISO/IEC 42001. These provide structured approaches for identifying and mitigating risks while fostering trust with customers and regulators. This is especially important as 80% of business leaders cite AI explainability, ethics, and trust as major barriers to adoption.
AI models thrive on quality data, and a well-structured pipeline ensures that data flows smoothly from source systems to AI applications. The challenge lies in creating pipelines that can handle massive data volumes while staying fast and dependable.
The first step is deciding between batch and streaming architectures. Batch pipelines process data at scheduled intervals - think hourly or daily - and are ideal for tasks like model training or historical analysis. Streaming pipelines, on the other hand, work in real time, processing data event by event. This makes them indispensable for applications like fraud detection or live recommendations.
Consider this: 68% of enterprise AI failures stem from data quality issues, not model performance. Even more alarming, 60% of AI projects are expected to stall by 2026 due to late, messy, or biased data. These numbers highlight the importance of building reliable pipelines.
Selecting the right pipeline depends on how quickly your AI workload needs data. Batch pipelines are straightforward to maintain and work well for training models on historical data where real-time accuracy isn't a priority. In contrast, streaming pipelines excel in handling high-speed data - like IoT sensors or clickstreams - delivering near-instant responses for operational AI.
Batch processing typically follows an extract–transform–load (ETL) cycle. Streaming, however, demands specialized skills to manage complexities like out-of-order events, state management, and ensuring exactly-once processing. Interestingly, integrating AI-powered methods into streaming pipelines can improve data throughput by 40% and reduce latency by 30%.
"Pipelines are no longer passive plumbing. They're alive. AI workloads are dynamic. Enrich. Label. Contextualize. Repeat. Or die."
- Lee James, Senior Partner, Domo
Many organizations are now adopting a hybrid approach: using batch pipelines for training and feature engineering while relying on streaming pipelines for real-time inference. Tools like Apache Iceberg and Delta Lake enable both batch and streaming workloads to share a single source of truth, eliminating data duplication and versioning conflicts.
Real-time synchronization is a key addition to these strategies, ensuring AI models always operate with the most up-to-date data.
Real-time synchronization ensures your AI models stay current with the latest data. Change Data Capture (CDC) is a popular technique for achieving this. By leveraging transaction logs - such as PostgreSQL WAL or MySQL binlog - CDC delivers near real-time updates without directly querying production tables. This method captures every change, including DELETE operations often missed by batch processes, while keeping source performance intact.
To improve resilience, decouple producers and consumers using message buses like Apache Kafka or AWS Kinesis. In this setup, producers send events without waiting for downstream processing, while the message bus stores events for replay if needed. This architecture supports event-driven AI applications, enabling immediate actions like real-time personalization or anomaly detection.
Designing tasks for idempotency - so they can be retried without unwanted side effects - helps prevent duplicates and ensures consistent outcomes. Pair this with automated retries using exponential backoff and Dead-Letter Queues to isolate problematic records without disrupting the entire pipeline.
These practices are essential for building AI-ready infrastructure that minimizes delays and ensures high-quality data.
To keep data pipelines running smoothly, robust fault tolerance and monitoring are essential safeguards against unexpected disruptions.
Start with redundancy by distributing deployments across multiple availability zones and using multi-regional storage for datasets and checkpoints. Implement horizontal autoscaling to dynamically adjust processing power based on CPU usage and data volumes.
The circuit breaker pattern is another effective strategy. It isolates faulty components in distributed systems, preventing cascading failures. Set error rate and latency thresholds to automatically reroute traffic away from unhealthy services until they recover. For long-running training tasks, asynchronous checkpointing allows pipelines to resume from the last stable state after interruptions.
"Running pipelines as service principals is considered a best practice because they are not tied to individual users, making them more secure, stable, and reliable for automated workloads."
- Databricks
Monitoring should go beyond standard metrics. Keep an eye on data drift, prediction drift, and model performance degradation - all of which are critical for AI workloads. Set up proactive alerts for latency, error rates, and GPU/TPU usage to catch issues early. Additionally, nightly canary evaluations - replaying live prompts against previous model versions - can help identify quality regressions before they escalate.
AI models rely on data from a variety of sources, including on-premises databases, cloud storage, edge devices, and APIs. The real challenge? Bringing all this data together without creating duplicates or inconsistencies. In fact, 70% of organizations adopting generative AI face hurdles with data governance and integration. It's no wonder so many AI projects struggle to move beyond the proof-of-concept stage.
One way to tackle these challenges is by establishing a single source of truth. Make the cloud your central hub for AI assets, ensuring all requests are handled from this primary copy or its approved derivatives. To keep things organized, use a unified metastore to manage metadata for your tables, models, and files. This approach streamlines naming conventions and reduces confusion.
Another helpful strategy is adopting a Medallion Architecture. This framework organizes data into three layers:
This step-by-step refinement ensures your AI models are working with high-quality, reliable data.
For many organizations, data lives in hybrid environments - split between on-premises systems and the cloud. While this setup offers flexibility, it also demands careful planning. For high-volume, real-time processing, dedicated connections like Azure ExpressRoute or AWS Direct Connect can bypass the public internet, ensuring consistent performance. For smaller or less frequent data transfers, VPN gateways offer a cost-effective alternative.
To boost reliability, consider deploying AI workloads across at least two regions. This setup not only enhances availability but also allows you to create separate management groups for external-facing and internal operations, reducing the risk of exposing sensitive business data. A federated data mesh approach can further improve efficiency by letting individual domain experts manage their own data while adhering to central governance policies.
"Data is not a by-product - it is a business asset with its own lifecycle."
These strategies lay the foundation for a more robust data integration process, but improving how you transfer and store data can further optimize your AI infrastructure.
Efficient data management means transferring and storing only what’s necessary. For example, if your AI model only needs city names, there’s no need to store full addresses with extra details. Eliminating redundant or low-quality data not only cuts storage costs but also speeds up processing.
When dealing with massive datasets - think 10 TB per day or more - parallel I/O becomes critical to avoid performance bottlenecks. Tools like Amazon S3 File Gateway or FSx for Lustre can cache frequently accessed data near compute resources, significantly reducing training times.
In cloud-to-training workflows, using Fast File mode allows data to stream directly from cloud storage as your training script processes it. This reduces startup delays and minimizes the need for large amounts of local storage. Compressing data with formats like Delta Parquet can also shrink storage requirements and speed up transfers.
Finally, automated data lifecycle management can help keep storage costs under control. By moving infrequently accessed data to cold or archive storage tiers and deleting outdated processing copies, you can prevent unnecessary expenses from piling up.
AI workloads are demanding - they rely on infrastructure that can handle massive datasets and intensive processing tasks. Striking the right balance between performance and cost is crucial. Your choices for storage and compute directly influence training speed, costs, and GPU utilization. For example, enterprise GPU utilization can plummet to just 15–20% when legacy systems fail to deliver data quickly enough.
Different AI workloads require different storage solutions, depending on the stage of the process. Here's a breakdown:
For the most demanding tasks, such as deep learning training with small files and random I/O, parallel file systems like Managed Lustre are a top choice. They offer sub-millisecond latency and throughput reaching up to 1 TB/s. These systems are POSIX-compliant, so they integrate seamlessly with traditional AI frameworks. Using high-performance storage for model checkpoints reduces downtime during training and boosts GPU utilization.
On the other hand, object storage - like S3, Azure Blob, or Google Cloud Storage - is better suited for large files (50 MB or more) and sequential access patterns. It’s more budget-friendly per gigabyte and can scale to exabytes of data. However, its latency - measured in tens of milliseconds - makes it unsuitable for intensive training operations. For frequently accessed data, SSD-backed zonal read caches can significantly improve throughput, reaching up to 2.5 TB/s.
| Storage Type | Best For | Latency | Cost per GB |
|---|---|---|---|
| Local NVMe/SSD | Ultra-intensive training, real-time inference | Ultra-low (sub-ms) | High |
| Parallel File Systems | Small files, random I/O, checkpointing | Sub-1 ms | Medium-High |
| Object Storage | Large files, archiving, backups | Tens of ms | Low |
Not every piece of data needs to occupy premium, high-performance storage. Here’s how you can optimize:
Automating lifecycle policies can help manage this process. For instance, you can set policies to migrate inactive data (e.g., after 30 days of inactivity) to more economical storage options. Deleting temporary files and intermediate preprocessing outputs once they’re no longer needed can further reduce storage costs.
Data versioning is another key practice. It helps track changes in datasets and models over time, enabling rollbacks, improving reproducibility, and facilitating collaboration without duplicating entire datasets. When new data arrives, consider isolating it on separate branches for validation before merging it into production. This approach prevents poor-quality data from corrupting your active datasets.
While optimizing storage and data management is crucial, don’t overlook the importance of security.
Security is non-negotiable. Thirteen percent of organizations have reported breaches involving AI models or applications, and 97% of those lacked proper AI access controls. Even more alarming, 8% of organizations are unaware if their AI models have been compromised.
Here’s how to secure your data infrastructure:
Confidential Computing adds another layer of protection, safeguarding data during processing through hardware-based isolation. Encrypting model checkpoints during training can help protect intellectual property. Additionally, multi-factor authentication should be mandatory for anyone managing deployment pipelines or accessing high-performance storage.
Building an infrastructure that's ready for AI means rethinking how enterprise data is managed. Did you know that about 90% of AI and generative AI projects never make it past the proof-of-concept stage? The main culprit: a lack of proper preparation.
To avoid this pitfall, focus on creating a scalable architecture with strong governance and seamless integration. Move away from centralized, batch-processing systems and adopt a federated data ownership model. This approach lets domain experts manage their own data while adhering to central policies. Real-time streaming pipelines are also key - go beyond structured tables and handle multimodal data effectively. Automating data quality checks and metadata management can help catch problems early, ensuring your models run smoothly. These strategies form the backbone of a data infrastructure capable of supporting AI.
"AI is only as good as the data that fuels it - and organizations will need to focus on building a robust, scalable, and unified data foundation." - Google Cloud
Start small by targeting high-impact use cases like fraud detection or churn prediction to demonstrate ROI before scaling up. Conduct audits to break down data silos and eliminate bottlenecks, creating a single source of truth that unifies all data types without unnecessary duplication. Treating data as a product - with clear ownership, quality standards, and a defined business purpose - can transform how your organization handles information.
Organizations that succeed in this area treat infrastructure preparation as a strategic advantage. With 84% of global businesses believing AI will give them a competitive edge, the real question is no longer if you should prepare your data infrastructure, but how quickly you can get started.
For tailored AI-ready data infrastructure solutions, consider partnering with Artech Digital.
A well-structured data governance framework is crucial for creating dependable and effective AI systems. It ensures your data is accurate, consistent, secure, and compliant, turning raw data into reliable resources for training AI models and making informed decisions.
Here’s what a strong framework can do for you:
Artech Digital specializes in crafting AI-ready data governance strategies, helping U.S. companies create secure, compliant, and high-performing AI solutions.
Selecting the right data pipeline comes down to understanding your AI use case and day-to-day operational demands. Ask yourself: How fast does the data need to be updated? How much data are we dealing with? How much latency can the AI workload handle?
If your AI model doesn’t rely on real-time updates - think daily recommendation engines or periodic fraud detection - batch pipelines might be your best bet. They’re straightforward, cost-efficient, and easier to maintain, working on scheduled processing and handling data in bulk. On the other hand, AI systems that demand real-time decisions - like dynamic pricing, instant personalization, or autonomous operations - will need a streaming pipeline. These pipelines deliver low-latency updates, ensuring your models stay in sync with the most current data.
To make the right choice, align your AI needs with latency requirements and determine whether your data sources generate continuous event streams or operate in batches. You can also consider a hybrid setup - using batch pipelines for large-scale model training while leveraging streaming for real-time updates to inference systems. Artech Digital specializes in designing and fine-tuning pipelines to meet your business objectives while adhering to compliance standards.
To improve data security in AI infrastructure, it's essential to adopt a secure-by-design approach that protects data at every stage of its lifecycle. This means encrypting data both when stored and while being transmitted, and using digital signatures to maintain its integrity. Implement strict access controls based on Zero-Trust principles, ensuring users and systems only have the minimal privileges needed and are continuously authenticated.
Safeguard the data pipeline and training environments by isolating resources, utilizing hardened containers or virtual machines, and keeping an eye out for unusual activity. Protect model artifacts by storing them in encrypted environments, maintaining version control, and using tamper-evident logging. These same precautions should extend to the deployment phase as well. Additionally, employ continuous monitoring to log access events, audit compliance, and identify suspicious behavior. Embedding governance practices ensures adherence to privacy regulations and provides oversight of data usage.
Artech Digital offers support in building AI-ready pipelines equipped with advanced security measures like encryption, Zero-Trust networking, and automated compliance monitoring. They also deliver tailored AI models designed to meet rigorous security requirements.
.png)

.png)